{kind=link}
The OpenAI API is celebrated for its impressive capabilities, but many users have reported slower response times. This article delves into common concerns regarding the API’s speed, offers solutions for enhancing performance, and emphasizes the importance of community feedback and engagement.

Understanding the OpenAI API
Before diving into optimization techniques, it’s crucial to understand the OpenAI API’s architecture and capabilities.
-
Model Selection: The OpenAI API offers a range of models, each with unique strengths and limitations. Choosing the right model for your specific task is paramount.
-
API Calls: Every interaction with the OpenAI API involves sending a request and receiving a response. Understanding the structure of these requests and responses is essential for efficient API usage.
Understanding the Speed Issues
Why is the OpenAI API Slow?
Users often question why the OpenAI API can be sluggish. Several factors contribute to this, including network latency, server load, and the complexity of the prompts being processed. Recognizing these elements is essential for identifying effective solutions.
-
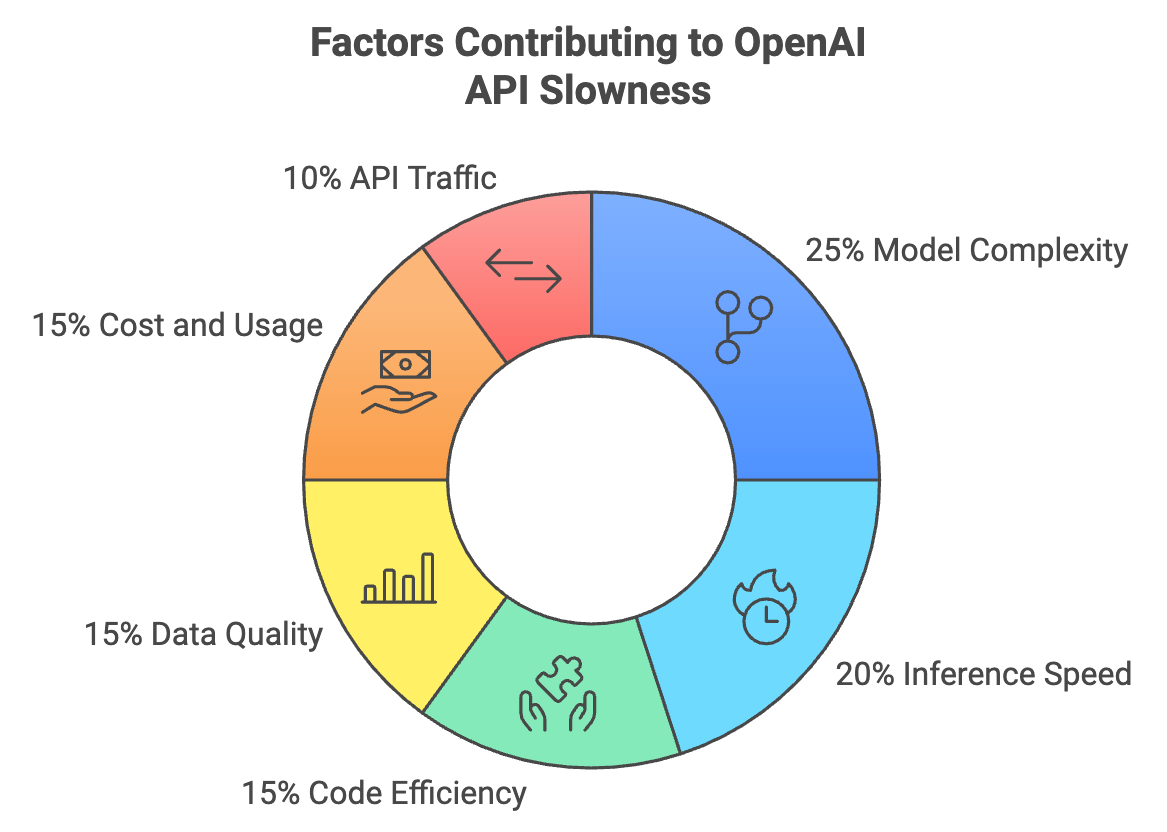
Model complexity: Larger models, like GPT-4, typically require more processing time and can be slower than smaller models, like GPT-3.5-turbo. This is because larger models have more parameters to compute, which increases the inference time.
- Inference Speed: This is the rate at which the language model processes tokens, measured in tokens per minute (TPM) or tokens per second (TPS). More complex tasks or longer content lengths may require more tokens to be processed, leading to slower response times.
- Code Efficiency: Inefficient code on your end can lead to unnecessary processing delays, even if the API itself is fast.
-
Data quality: Poor-quality input data can negatively impact the API’s performance. Ensuring high-quality input data and implementing data cleaning and preprocessing techniques can help maintain optimal output and processing efficiency.
-
Cost and usage: Faster models or more frequent API calls generally incur higher costs. Balancing the need for speed with budget constraints is essential. Consider using smaller models or implementing caching strategies to optimize both latency and cost.
- API Traffic: High demand on the OpenAI API can lead to congestion and slower response times, especially during peak usage periods.
Strategies for Improving API Response Times
Best Practices for Performance
To optimize the speed of OpenAI API interactions, consider the following strategies:
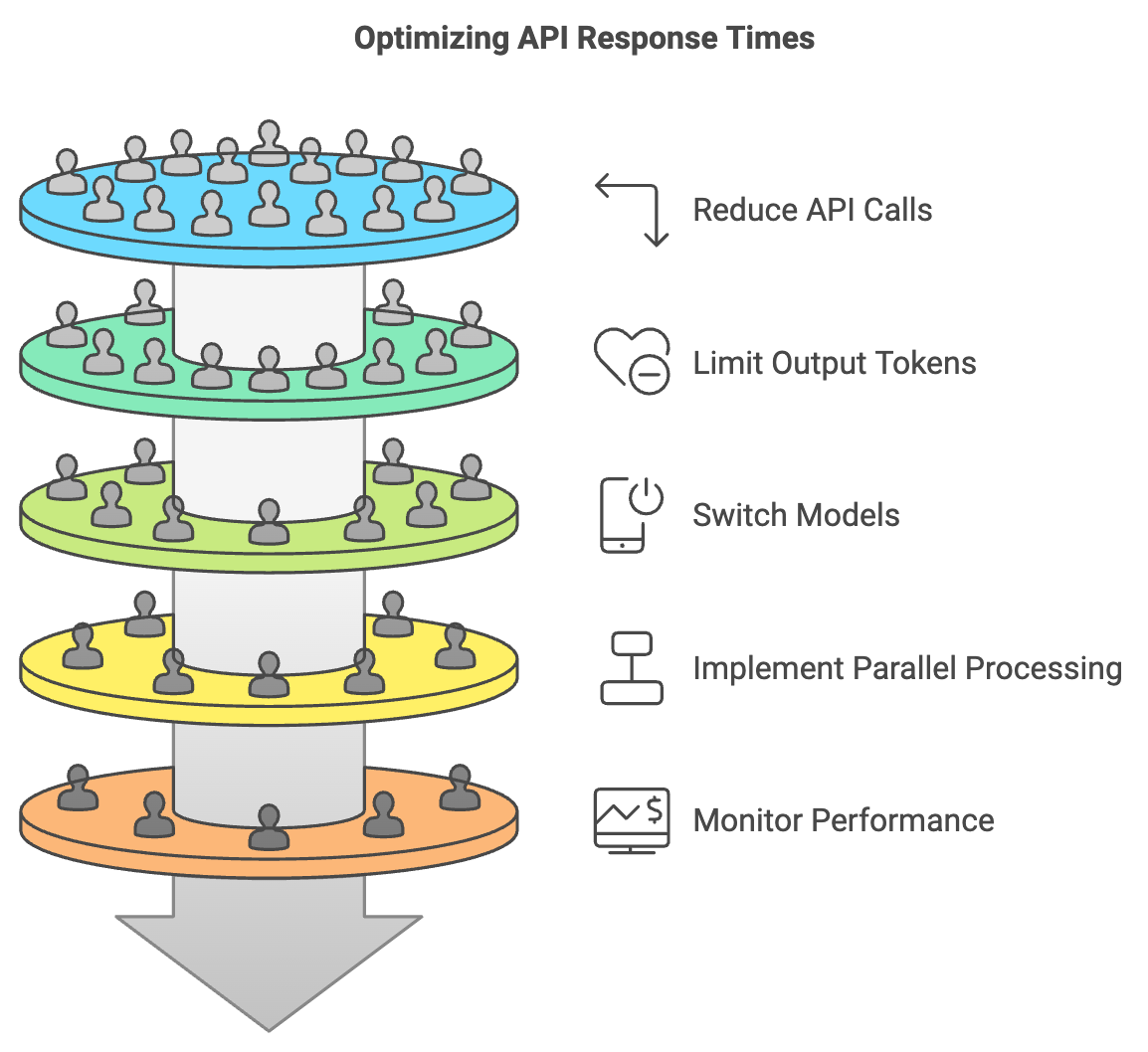
- Reduce the Number of API Calls: Making fewer requests can significantly decrease response times.
- Limit Output Tokens: Requesting fewer tokens in responses can expedite the process.
- Request One Token at a Time: This approach can streamline interactions and reduce wait times.
- Switch to a Different Model: Transitioning from GPT-4 to GPT-3.5 may provide faster responses.
- Utilize Azure API: Opting for Azure’s infrastructure might improve performance for some users.
- Implement Parallel Processing: Running multiple requests simultaneously can optimize overall efficiency.
- Stream Output with Stop Sequences: This technique allows for quicker delivery of results.
- Consider Alternative Approaches: Exploring other tools or methods, such as Microsoft Guidance, can also be beneficial.
-
Caching: Cache frequently used API responses to reduce latency and API calls.
-
Batching Requests: Send multiple API requests in a single batch to improve efficiency.
-
Monitoring and Analysis: Track API performance metrics (e.g., response times, error rates) to identify bottlenecks and areas for improvement.
“The way you phrase your prompt is like giving directions to a very intelligent but literal-minded assistant. Be clear, be concise, and be specific.” – OpenAI Documentation
Latency Optimization
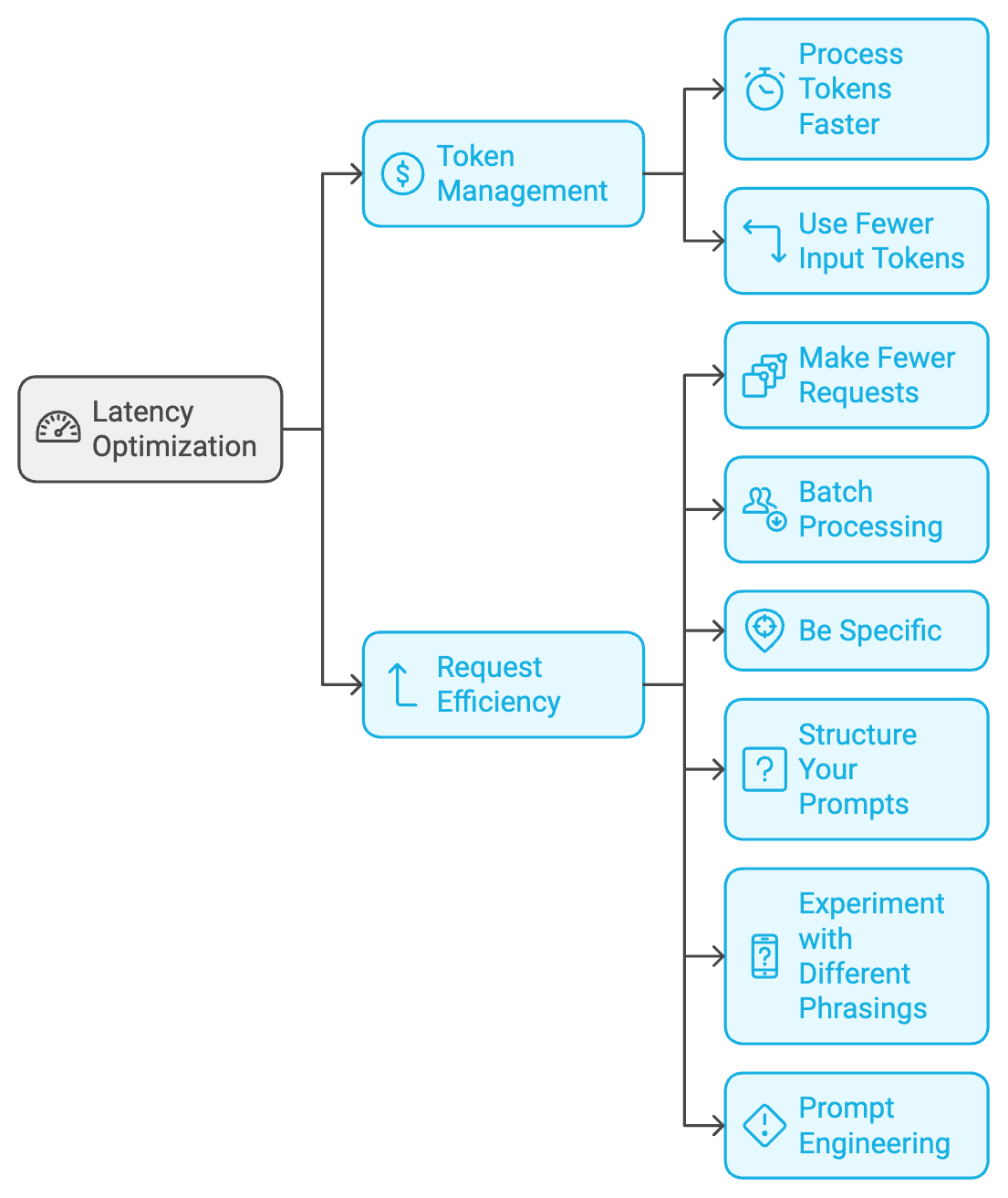
- Token Management:
- Process Tokens Faster: Minimize the number of tokens processed by the model (e.g., generate fewer output tokens).
- Use Fewer Input Tokens: Craft concise and relevant prompts to reduce input token count.
- Request Efficiency:
- Make Fewer Requests: Combine sequential tasks into single requests to reduce round-trip latency.
- Batch Processing: Utilize the Batch API for asynchronous processing of groups of requests, improving throughput for non-time-sensitive applications.
- Be Specific: Clearly define the task you want the model to perform. Avoid ambiguity and provide all necessary context.
- Structure Your Prompts: Use proper grammar and sentence structure. Break down complex tasks into smaller, manageable steps.
- Experiment with Different Phrasings: Slight variations in wording can lead to significantly different results. Test different prompts to see what yields the best output.
- Prompt Engineering: Carefully design prompts to elicit efficient processing from the API.
The quality of your input directly impacts the quality of the output.
Cost Management Strategies
- Simplify Your JSON: Remove unnecessary data from your API requests to reduce payload size and costs.
General Tips
- Effective Communication: Ensure clear and concise communication with the API to avoid unnecessary load and costs.
-
Stay Updated: The OpenAI API is constantly evolving. Stay informed about new features, updates, and best practices.
-
OpenAI Usage Visibility:
- OpenAI’s management panel provides basic visibility, including monthly billing.
- You can request access to Datadog’s dedicated OpenAI dashboard for real-time tracking of API calls and token requests.
- For the best visibility, track OpenAI’s three rate limits (RPD, RPM, and TPM) yourself.
These services and strategies can help you improve optimization when using the OpenAI API, focusing on cost management, performance enhancement, and efficient resource utilization.
Key Takeaways
- Token Management: Processing fewer tokens and using concise prompts.
- Request Efficiency: Making fewer requests and utilizing batch processing.
- Cost Management: Simplifying JSON payloads and communicating effectively with the API.
- Respect the Limits: Adhere to the API’s rate limits to avoid getting temporarily blocked.
- Implement Backoff Strategies: If you encounter rate limits, implement exponential backoff strategies to retry requests at increasing intervals.
Engaging with the Community

Provide Feedback and Utilize Saved Searches
Engaging with the user community through feedback is crucial. By sharing experiences and solutions, users can help enhance the API’s performance. Additionally, using saved searches can streamline the process of finding relevant information or discussions on similar issues.
Our Services
In addition to optimizing API performance, we offer a range of services designed to support your business needs:
Backend API Solutions
We deliver robust backend solutions that facilitate seamless interactions between front-end applications and data sources. Our services lay the groundwork for a responsive and agile business environment, ensuring your applications run smoothly and efficiently.
Conclusion
Improving the performance of the OpenAI API involves understanding the factors behind slow responses and implementing effective strategies. By actively participating in the community and providing feedback, users can contribute to ongoing enhancements, ensuring a more efficient experience for everyone. Additionally, our backend API solutions can help streamline your operations, allowing you to focus on growth and innovation.
Frequently Asked Questions
To reduce latency when using the OpenAI API, consider implementing the following strategies:
Caching: Store frequent requests and responses to minimize redundant API calls.
Batch Requests: Group multiple requests into a single API call to optimize performance.
Code Optimization: Write efficient code to reduce processing time and enhance overall response speed.
Temperature controls the randomness of the model’s output; higher values increase diversity, while lower values yield more focused and deterministic results. Top_k limits the model’s consideration to the most likely words, narrowing down options for each token generation step.
To manage API rate limits effectively, implement exponential backoff strategies. This involves retrying requests at increasing intervals after encountering rate limit errors, ensuring a smooth request flow without overwhelming the API.
The GPT-4 Turbo model can process up to 128k tokens, allowing for extensive input and output in a single request, significantly enhancing its capability for handling longer content compared to earlier models.
Notable pre-trained models available in the OpenAI API include DALL-E for image generation and Codex for code completion, catering to various use cases in creative and programming tasks.
Top_p (nucleus sampling) complements top_k by allowing the model to consider a dynamic number of tokens based on cumulative probability. This can lead to more coherent outputs by focusing on a broader range of likely options without being overly restrictive.
Yes, you can customize parameters like temperature and top_k to tailor the model’s responses for specific applications. For example, setting a lower temperature can yield more reliable outputs for factual queries, while a higher temperature may be suitable for creative writing tasks.
Best practices include:
Thoroughly Read Documentation: Familiarize yourself with API capabilities and limitations.
Monitor Usage: Keep track of your API usage to avoid hitting rate limits.
Test Different Parameters: Experiment with temperature, top_k, and other settings to find optimal configurations for your specific needs.