{kind=link}
Web Scraping with Playwright and Scrapy: A Comprehensive Guide
In today’s digital landscape, many websites are constructed as JavaScript Single-Page Applications (SPAs), which dynamically update content through XMLHttpRequests (XHR). This modern approach presents a significant challenge for traditional web scraping techniques, which often fail to capture the dynamically loaded data.
This blog post delves into how to tackle this challenge by leveraging automated browsers for web scraping. While this method may be slower and more complex to scale compared to others, it offers a robust solution for various applications. We will focus on two powerful Python libraries – Playwright and Scrapy – to illustrate the process.
Highlights
🌐 Dynamic Websites: Many sites use JavaScript and XHR, complicating traditional scraping.
🕷️ Automated Browsers: Playwright is used for scraping, offering a solution for dynamic content.
📊 IP Royal: A recommended proxy provider for reliable residential IPs.
🔄 Data Extraction: Combines HTML parsing with browser automation to extract data effectively.
🎬 Pagination Handling: Demonstrates how to navigate through paginated content efficiently.
⚙️ Scrapy Integration: Shows how to set up Scrapy with Playwright for enhanced scraping capabilities.
🧩 JavaScript Execution: Utilizes JavaScript to handle infinite scrolling on web pages.
Key Insights
📈 Scraping Challenges: Traditional scraping techniques often fail on dynamic sites, requiring more advanced methods like browser automation. This highlights the need for adaptable scraping strategies.
🛠️ Playwright Advantages: Playwright provides a powerful tool for automating browsers, making it easier to interact with web pages. Its ability to execute JavaScript is crucial for modern web scraping.
🔒 Proxy Importance: Using high-quality residential proxies, such as those from IP Royal, ensures anonymity and reduces the risk of IP bans during scraping operations.
📚 HTML Parsing Techniques: The integration of lightweight parsers like Selectolax allows for efficient data extraction from HTML, showcasing the importance of choosing the right tools for specific tasks.
🔄 Efficient Pagination: Implementing logic to handle pagination effectively reduces manual effort and improves the scraping process, making it more automated and scalable.
🔗 Scrapy and Playwright Synergy: Combining Scrapy with Playwright enhances the scraping framework’s capabilities, allowing for more complex scraping scenarios that involve JavaScript-rendered content.
🚀 Performance Trade-offs: While browser automation is effective, it can slow down scraping operations and complicate scaling. Understanding these trade-offs is essential for optimizing scraping projects.
Challenges of Scraping Modern Websites
Traditional web scraping methods, which focus on fetching and parsing static HTML, often fall short when dealing with modern websites that use JavaScript and dynamic content loading. These websites frequently employ XHR requests to fetch data from backend servers, updating the frontend without a full page reload. Consequently, scrapers that rely solely on static HTML parsing may overlook critical information or receive incomplete data.
Consider a website that displays a list of products, with additional items loaded dynamically as the user scrolls. A traditional scraper might capture only the initial set of products visible upon the first page load, missing the subsequent products loaded asynchronously. This limitation underscores the necessity for advanced scraping techniques capable of handling dynamic content and mimicking user interactions.
Leveraging Automated Browsers for Web Scraping
An effective strategy for scraping dynamic websites involves using an automated browser. This method involves employing a tool that can control a web browser programmatically, enabling you to navigate websites, interact with elements, and extract the necessary data. Automated browsers can mimic human behavior, making it possible to scrape content that becomes available only after specific actions or interactions.
Although this approach may be slower and more resource-intensive compared to traditional scraping methods, it offers significant advantages. Automated browsers can manage JavaScript, cookies, and other browser-specific features, allowing access to data that would otherwise be inaccessible. They can also simulate user interactions, such as clicking buttons, filling out forms, and scrolling through pages, enabling the extraction of data from websites that rely on dynamic loading.
However, it’s important to recognize that automated browser-based scraping can be more complex to implement and scale. Managing multiple browser instances, addressing potential errors, and ensuring efficient resource utilization can be challenging. Therefore, it’s essential to carefully weigh the trade-offs before choosing this approach.
Using Playwright for Web Scraping
Playwright is a robust Node.js library offering a high-level API for controlling web browsers. It supports Chromium, Firefox, and WebKit, making it a versatile tool for web scraping across various platforms. Playwright’s API is designed to be user-friendly, enabling you to automate browser interactions with minimal effort.
In this section, we will guide you through a practical example of using Playwright to scrape data from a website. Specifically, we will demonstrate how to extract product information, including names and prices, from a test e-commerce site. We will cover loading the page, extracting the desired data, and managing pagination to retrieve all available products.
Parsing HTML with Selectolax
Before delving into Playwright, let’s discuss how we will parse the HTML content extracted from the website. We will use Selectolax, a lightweight and efficient HTML parser that leverages CSS selectors. Selectolax is particularly useful for quickly extracting specific elements from HTML based on their CSS classes or attributes.
In our example, we will define a function called parse_item that takes the HTML content of a page as input. This function will use Selectolax to locate the product information within the HTML and extract the relevant data. The extracted data will be stored in a dictionary, with keys representing the data fields (e.g., “title” and “price”) and values representing the corresponding data extracted from the HTML.
Controlling the Browser with Playwright
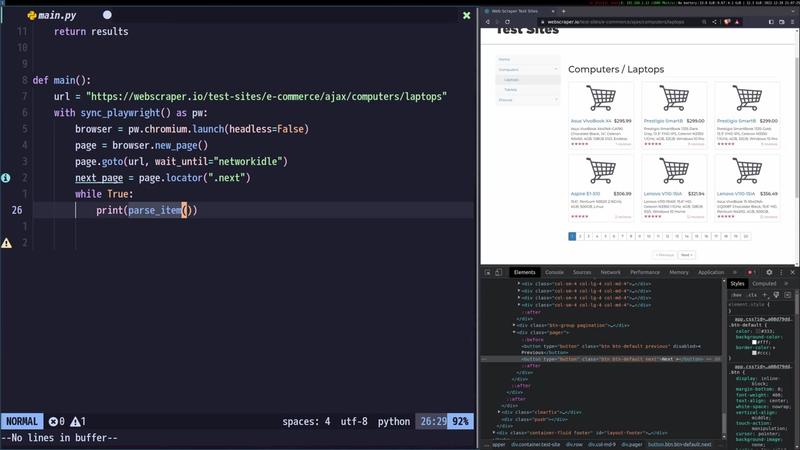
Now, let’s explore how to control the browser using Playwright. We will begin by launching a Chromium browser instance in headless mode. Headless mode means the browser window will not be visible, which is ideal for automated tasks. However, for demonstration purposes, we can set headless=False to visualize the browser’s actions.
Next, we will create a new page within the browser and navigate to the target website using the page.goto() method. We will also use the wait_for_load_state option with 'networkidle' to ensure that the page has fully loaded before proceeding. This option waits until there is no network activity for a certain period, indicating that the page has finished loading all its resources.
Handling Pagination with Playwright
Many websites use pagination to display large amounts of data across multiple pages. To scrape all the data, we need to handle the pagination mechanism. In our example, the website has a “Next” button that allows users to navigate to the subsequent pages. We will use Playwright’s locator functionality to identify the “Next” button and click it repeatedly until we reach the end of the pagination.
To determine when to stop clicking the “Next” button, we will check if the button is disabled. If the button is disabled, it indicates that we have reached the last page. We can achieve this by using Playwright’s is_disabled() method on the “Next” button locator. Once the button is disabled, we will break out of the loop that is responsible for clicking the “Next” button.
Web Scraping with Scrapy and Playwright
Scrapy is a widely-used Python framework for web scraping, known for its robustness and efficiency in extracting data from websites. Its scalable architecture allows you to define spiders that crawl through websites and extract the desired data. In this section, we will explore how to integrate Scrapy with Playwright to scrape data from websites that employ infinite scrolling.
Setting up Scrapy and Playwright
To get started, we need to install Scrapy and the required Playwright dependencies. We will also create a new Scrapy project and a spider to manage the scraping process. The spider will specify the starting URL of the website and the logic for data extraction.
Before writing the spider, we must configure Scrapy to use Playwright as the download handler. This ensures that Scrapy leverages Playwright to render pages and handle JavaScript interactions. We will modify the settings.py file in our Scrapy project to include the necessary Playwright configurations.
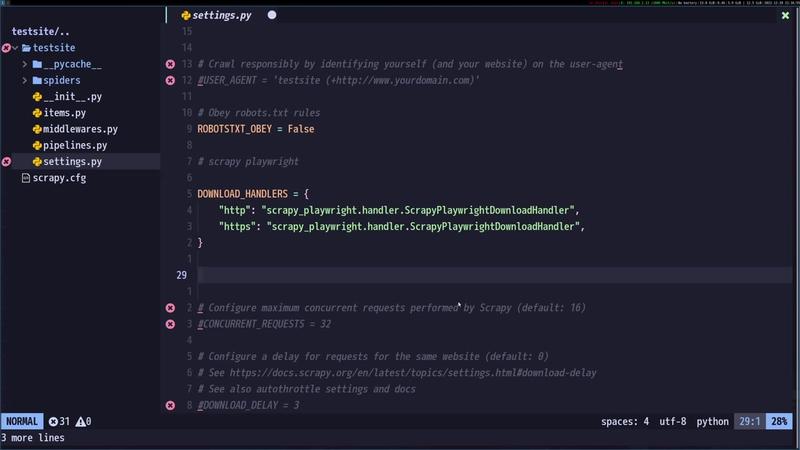
settings.py file with Playwright configuration.Implementing Scroll Functionality with Playwright
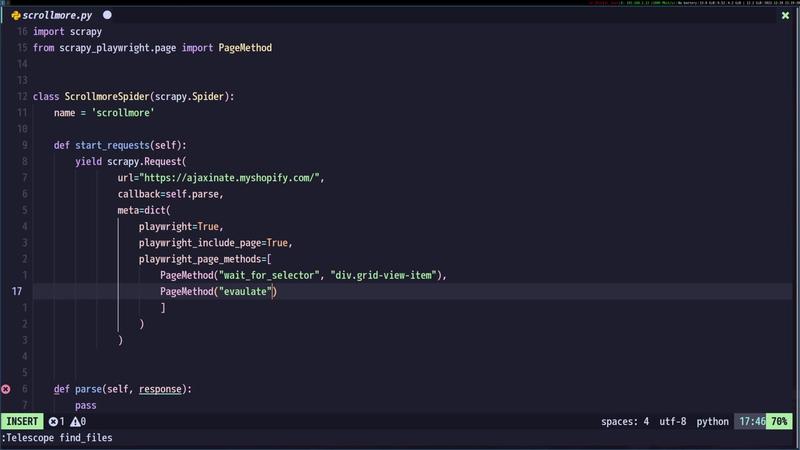
The website we are targeting uses infinite scrolling, where new content loads as the user scrolls down. To scrape all the data, we need to simulate scrolling to the bottom of the page. We will use Playwright’s page.evaluate() method to execute JavaScript code that automatically scrolls the page.
The JavaScript code will employ setInterval() to continuously scroll the page until it reaches the bottom. We will also use Playwright’s page.wait_for_load_state() method with 'networkidle' to ensure the page has fully loaded all content after each scroll operation.
Parsing Data in the Scrapy Spider
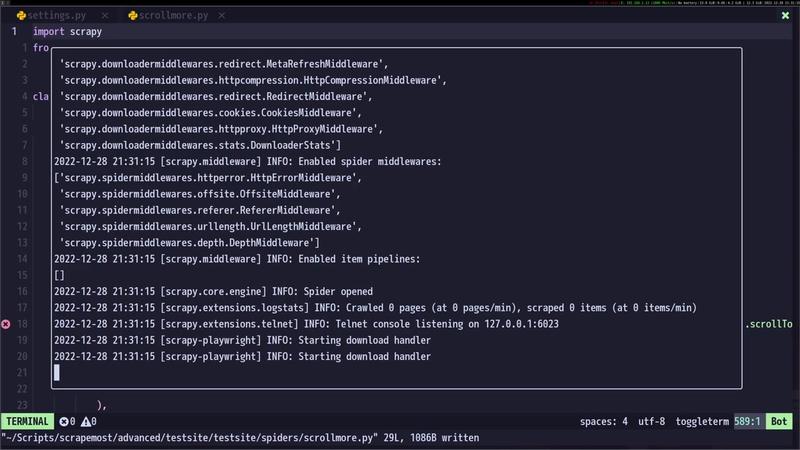
Once the page is fully loaded and scrolled to the bottom, we can parse the HTML content using Scrapy’s built-in parsing mechanisms. The parsing logic will be similar to the Playwright example, where we use CSS selectors to locate and extract the desired data. The extracted data will be yielded as items, which Scrapy will process and store in the desired format.
In this example, we will extract product names and prices from the HTML and yield them as items. Scrapy will then handle the storage of these items, potentially writing them to a CSV file or a database.
Conclusion
Throughout this blog post, we delved into the complexities of scraping modern websites that heavily rely on JavaScript and dynamic content loading. We showcased how automated browsers, particularly Playwright and Scrapy, can be harnessed to navigate these challenges. Although automated browser-based scraping may be slower and more resource-intensive compared to traditional methods, it offers a robust solution for extracting data from dynamic websites.
We covered the fundamental aspects of using Playwright to manage a browser and Scrapy to design spiders and extract data. Practical examples were provided, illustrating how to scrape data from websites featuring pagination and infinite scrolling. By mastering these techniques, you can efficiently gather data from a diverse array of websites, regardless of their technological intricacies.
It is essential to practice responsible web scraping. Always adhere to the website’s robots.txt file and terms of service. Avoid inundating the website with excessive requests and ensure that your scraping activities do not impair the website’s performance or inconvenience its users. By following ethical web scraping practices, you can utilize these powerful tools to collect valuable data for your projects while respecting the integrity of the websites you interact with.