{kind=link}
In the rapidly evolving landscape of web scraping and data collection, adherence to ethical standards and legal compliance is paramount. This comprehensive guide explores the best practices for ethical web scraping, with a particular focus on CAPTCHA handling, while considering the legal framework, technical aspects, and emerging trends in this field.
Legal Framework
United States Perspective
The legal landscape governing web scraping in the United States is complex, characterized by a patchwork of federal and state laws. The Computer Fraud and Abuse Act (CFAA) serves as a significant piece of legislation, though its application to web scraping activities remains subject to interpretation. A recent Supreme Court decision clarified that accessing information “without authorization” must be interpreted through a metaphor of gates, providing some guidance on the legality of certain scraping practices.
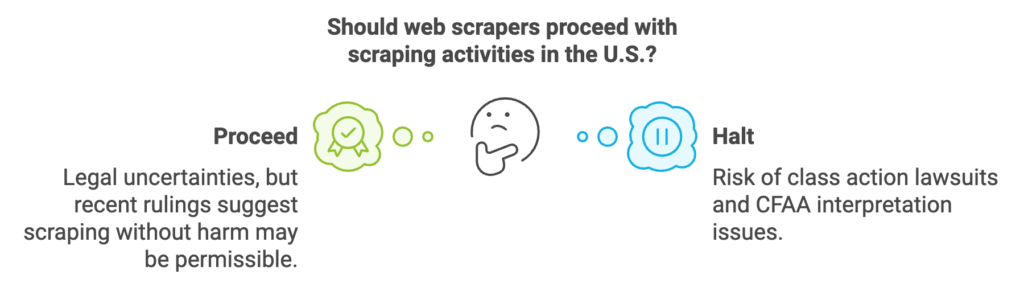
Class action lawsuits, such as those led by the Clarkson Law Firm against companies like OpenAI and Google, highlight the ongoing legal uncertainties surrounding web scraping. These cases often center on claims of “illicit data collection” and misuse of information, underscoring the need for clear legal precedents in this area.
The interpretation of a website’s terms of service (ToS) plays a crucial role in determining the legality of scraping activities. Recent rulings suggest that merely scraping a website without causing harm may not lead to prosecution under the CFAA, provided that the terms of service are not directly violated.
European Union Framework
In contrast to the United States, the European Union operates under a more cohesive legal structure, primarily governed by the General Data Protection Regulation (GDPR). The Court of Justice of the European Union (CJEU) has provided rulings that emphasize the tension between innovation and database rights, particularly in cases where content is aggregated from multiple sources.
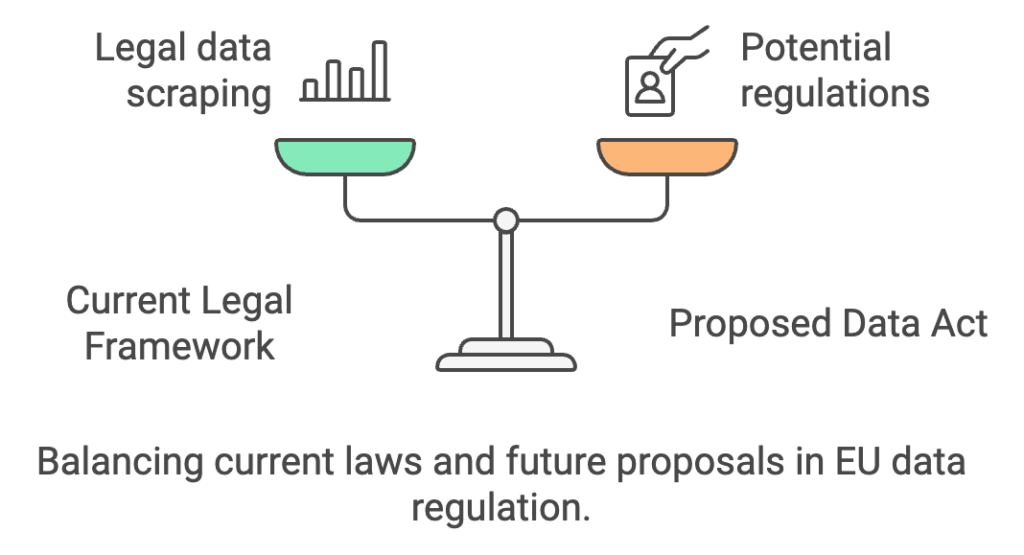
Under EU law, scraping public commercial data that does not fall under copyright or privacy protections is generally considered legal. However, ongoing legislative discussions, such as proposals for the Data Act, could further shape this landscape in the future.
Ethical Best Practices
Transparency and Consent
Ethical web scraping demands transparency in communicating activities, purposes, and data usage to all stakeholders. When collecting data related to individuals or sensitive topics, obtaining explicit consent is crucial to ensure that users are informed and agree to the data collection process.
Respect for Target Websites
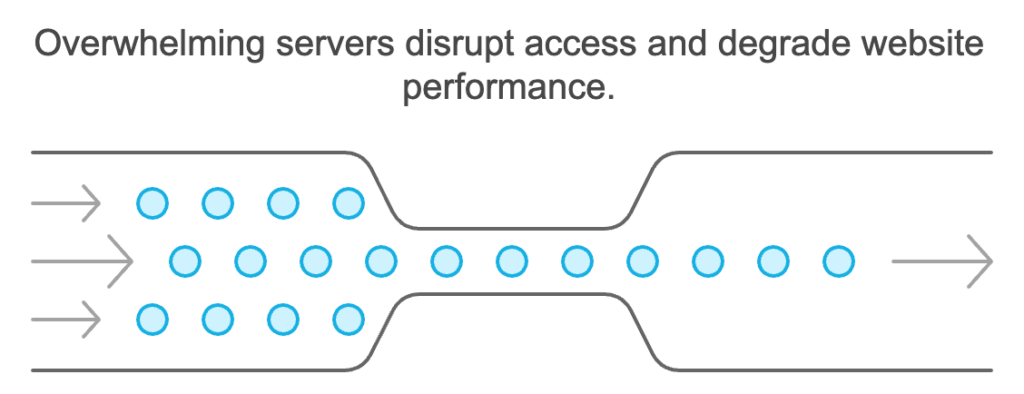
Scrapers must be mindful of the impact their activities have on target websites. This includes avoiding Denial-of-Service (DoS) attacks by not overwhelming servers with excessive requests. Utilization of the robots.txt file is recommended to respect the preferences of website owners regarding which parts of their site can be crawled.
Data Minimization and Retention
Collecting only necessary data and implementing strict data retention policies are essential practices. This approach helps mitigate concerns about surveillance and excessive data retention while aligning with data protection principles.
Legal Compliance
Scrapers must ensure their practices comply with relevant laws and regulations, including copyright laws and fair use policies. Staying informed about evolving ethical norms and legal frameworks surrounding data privacy and protection is crucial for maintaining compliance.
User-Centric Approach
Prioritizing user privacy and consent is fundamental to ethical web scraping. Companies should ensure that users are fully informed and have provided affirmative opt-in consent before their data is collected.
Resource Management
Effective resource management involves optimizing network requests and minimizing impact on target websites’ performance. Implementing rate-limiting strategies helps avoid overwhelming servers and reduces the risk of being blocked.
Continuous Improvement
The ethical landscape of web scraping is dynamic, requiring scrapers to adapt continuously. Engaging with the community, monitoring trends, and updating practices to align with changing societal expectations are essential for maintaining ethical standards.
Technical Considerations
Web Scraping Techniques
Advanced web scraping techniques involve developing human-like browsing patterns to reduce detection by anti-scraping technologies. Key strategies include implementing session management and introducing random delays between requests to mimic natural browsing behavior.
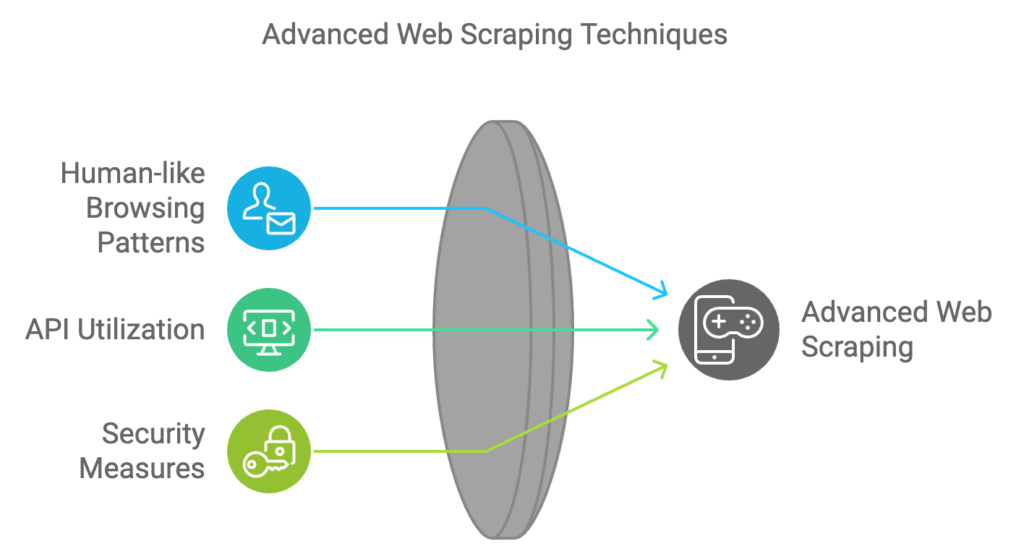
API Utilization
When available, utilizing APIs is often the most efficient and ethically sound method for data collection. APIs provide structured access to data without overwhelming servers, aligning with ethical scraping practices and data ownership policies.
Security Measures
Incorporating robust security measures, such as handling reCAPTCHA challenges, is crucial. Advanced solutions like CapSolver can efficiently navigate these security mechanisms while maintaining a balance between security and user experience.
CAPTCHA Handling
Anti-CAPTCHA Libraries and Services
To address the challenges posed by CAPTCHAs, several anti-CAPTCHA libraries and APIs have emerged. These tools utilize advanced algorithms and techniques to analyze and solve CAPTCHAs automatically, streamlining the scraping process.
CAPTCHA Solving Services
Third-party services specializing in CAPTCHA solving offer an alternative solution. These services employ human workers to manually solve CAPTCHAs, allowing scrapers to continue their operations without interruptions. While potentially costly, some services like Capsolver offer economical solutions for various CAPTCHA types.
Case Studies
1. HiQ Labs, Inc. v. LinkedIn Corp.: A Landmark Decision
The Ninth Circuit’s ruling in HiQ Labs, Inc. v. LinkedIn Corp. has set a significant precedent in the realm of web scraping. The court determined that scraping publicly accessible data from LinkedIn profiles does not violate the Computer Fraud and Abuse Act (CFAA). This decision has far-reaching implications:
- It affirms the principle that public data should remain accessible.
- It provides clarity for researchers and archivists who rely on web scraping for data collection.
- It challenges attempts by platforms to restrict access to public information through legal means.
2. Bright Data vs. Meta: Reinforcing Open Access
The legal confrontation between Bright Data and Meta (formerly Facebook) further underscores the ongoing debate over data scraping:
- Bright Data successfully challenged Meta’s demand to cease scraping data from its platforms.
- The court’s decision in favor of Bright Data reinforces the principle of open access to publicly available web information.
- This case highlights the tension between tech giants and data collection companies regarding control over public information.
3. Class Actions Against AI Companies: Navigating Uncharted Territory
Recent class action lawsuits filed by the Clarkson Law Firm against major AI companies like OpenAI and Google illuminate the current legal uncertainties:
- These lawsuits allege “illicit data collection” and misuse of “stolen information” in AI development.
- They represent millions of internet users and copyright holders.
- The outcomes of these cases may establish important precedents for future data scraping practices and ethics.
4. Privacy Concerns: The Clearview AI Controversy
The case of Clearview AI serves as a cautionary tale, illustrating the potential risks associated with aggressive web scraping:
- Clearview AI faced legal action for scraping billions of social media profile photos without consent.
- This case highlights the ethical implications of web scraping, particularly concerning sensitive personal data.
- It emphasizes the need for organizations to adhere to ethical practices and privacy standards in data collection.
5. Jurisdictional Variations: Navigating Global Complexities
The legal framework for web scraping varies significantly across different jurisdictions:
- In the European Union, violating a website’s terms of service is not considered a crime, contrasting with pre-2021 U.S. legal interpretations.
- This divergence complicates the legal landscape for scraping activities.
- Companies and individuals must carefully examine local laws and terms of service agreements before engaging in data collection efforts.
Related Articles:
Navigating the Challenges of Web Scraping: A Comprehensive Guide to CAPTCHA Solving Techniques