{kind=link}
In the ever-evolving landscape of the internet, data is the new currency. Whether you’re conducting market research, monitoring competitors, aggregating product prices, or performing sentiment analysis, web scraping has become an indispensable tool for extracting valuable information from websites. However, as websites become more sophisticated, traditional scraping methods often fall short. This comprehensive guide delves into advanced web scraping techniques, including handling JavaScript-rendered content, utilizing headless browsers, managing proxies, and more, establishing a robust foundation for anyone looking to master the art of web scraping.
Table of Contents
- Understanding the Basics
- Handling JavaScript-Rendered Content
- 2.1 [Why JavaScript-Rendered Content is Challenging]
- 2.2 [Techniques to Scrape JavaScript-Rendered Pages]
- Leveraging Headless Browsers
- 3.1 [What are Headless Browsers?]
- 3.2 [Popular Headless Browsers and Frameworks]
- 3.3 [Implementing a Headless Browser for Scraping]
- Proxy Management
- 4.1 [Why Use Proxies?]
- 4.2 [Types of Proxies]
- 4.3 [Rotating Proxies and IP Rotation Strategies]
- 4.4 [Implementing Proxy Management in Your Scraper]
- Dealing with Anti-Scraping Measures
- 5.1 [CAPTCHAs]
- 5.2 [Rate Limiting]
- 5.3 [Bot Detection Mechanisms]
- Optimizing Scraper Performance
- 6.1 [Concurrency and Asynchronous Processing]
- 6.2 [Efficient Data Storage]
- Ethical and Legal Considerations
- Top Tools and Libraries for Advanced Web Scraping
- Best Practices for Advanced Web Scraping
- Conclusion
Understanding the Basics
Before diving into advanced techniques, it’s essential to have a solid understanding of the fundamentals of web scraping:
- HTTP Requests: The backbone of web scraping involves sending HTTP requests to retrieve web pages.
- HTML Parsing: Once a page is fetched, its HTML content needs to be parsed to extract relevant data.
- Libraries and Tools: Tools like Beautiful Soup for Python, Cheerio for Node.js, and frameworks like Scrapy streamline the scraping process.
However, as websites incorporate dynamic content and sophisticated anti-scraping mechanisms, these basic methods often require enhancements to be effective.
Handling JavaScript-Rendered Content
2.1 Why JavaScript-Rendered Content is Challenging
Modern websites heavily rely on JavaScript to render content dynamically. Single Page Applications (SPAs) built with frameworks like React, Angular, or Vue.js load data asynchronously, making it difficult for traditional scrapers that fetch static HTML to access the desired information.
2.2 Techniques to Scrape JavaScript-Rendered Pages
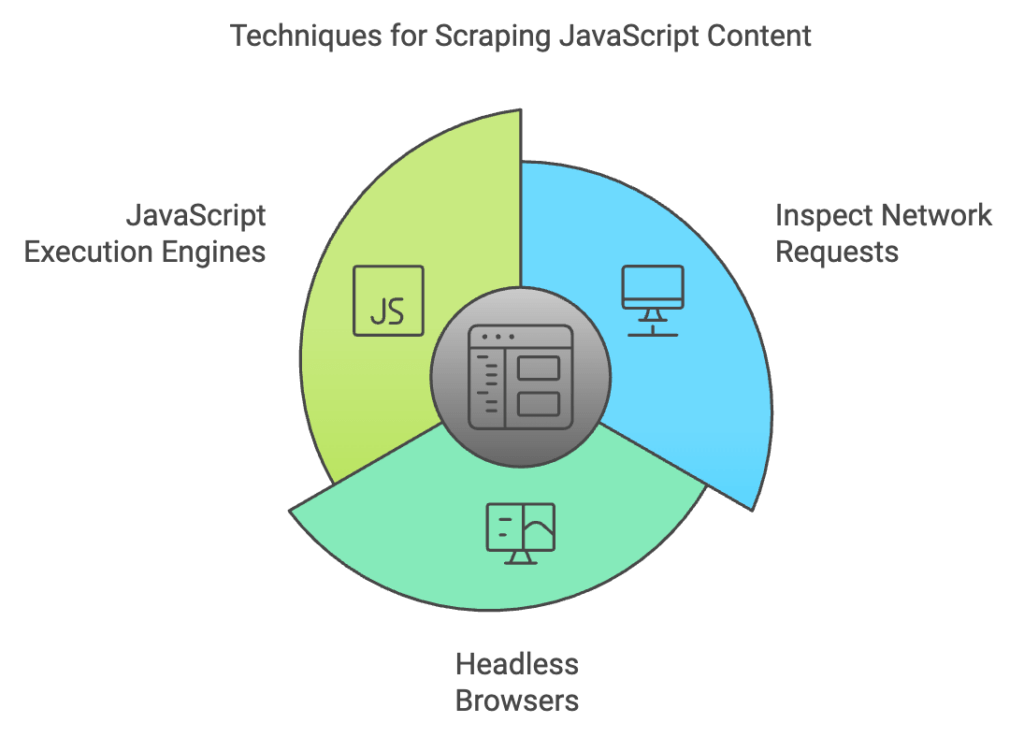
- Inspect Network Requests:
- Use browser developer tools to monitor XHR (XMLHttpRequest) or Fetch API requests that retrieve data.
- Identify API endpoints returning JSON or other structured data, allowing direct access without rendering the entire page.
- Headless Browsers:
- Utilize headless browsers (explained in the next section) to execute JavaScript and render dynamic content.
- JavaScript Execution Engines:
- Tools like PyV8 or JavaScriptCore can execute JavaScript within your scraping script, extracting dynamically generated content.
Leveraging Headless Browsers
3.1 What are Headless Browsers?
Headless browsers are web browsers without a graphical user interface. They operate programmatically, allowing scripts to interact with web pages similarly to how a user would, including running JavaScript, handling events, and manipulating the DOM.
3.2 Popular Headless Browsers and Frameworks
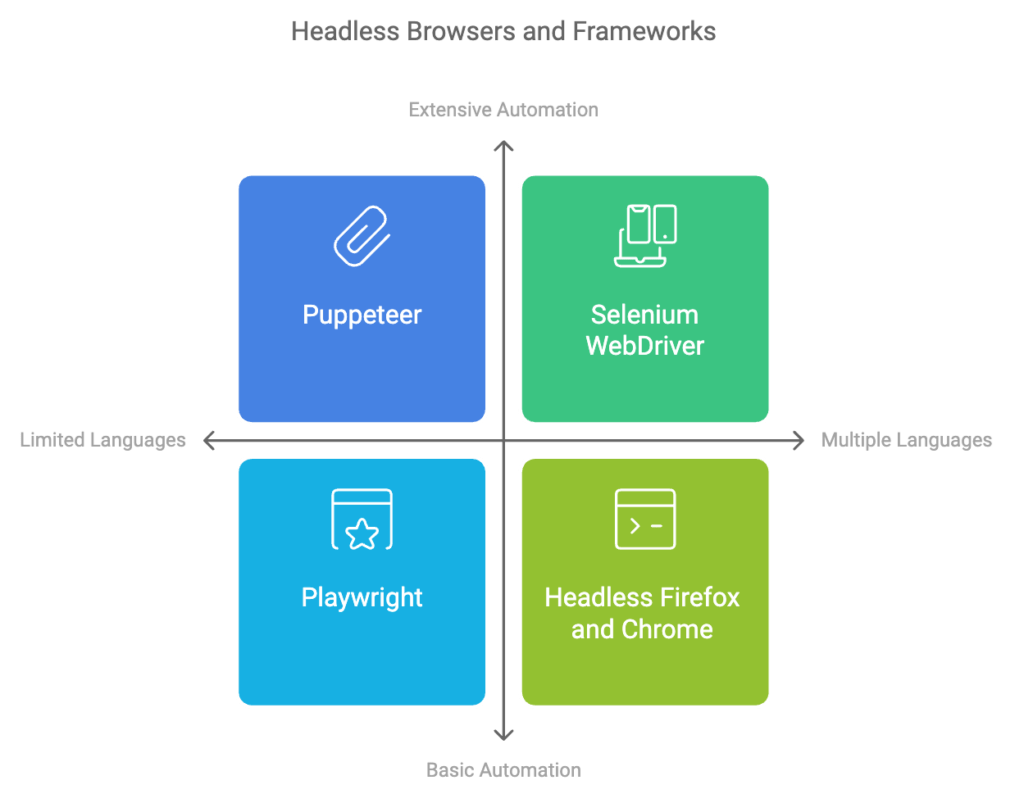
- Puppeteer: A Node.js library providing a high-level API to control Chrome or Chromium.
- Selenium WebDriver: Supports multiple browsers and programming languages, offering extensive automation capabilities.
- Playwright: Developed by Microsoft, it supports Chromium, Firefox, and WebKit with reliable automation features.
- Headless Firefox and Chrome: Native headless modes of these browsers can be controlled via command-line interfaces or APIs.
3.3 Implementing a Headless Browser for Scraping
Example: Using Puppeteer in Node.js
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://example.com', { waitUntil: 'networkidle2' });
// Extract content
const data = await page.evaluate(() => {
return document.querySelector('h1').innerText;
});
console.log(data);
await browser.close();
})();
Example: Using Selenium in Python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
driver = webdriver.Chrome(options=options)
driver.get('https://example.com')
# Extract content
data = driver.find_element_by_tag_name('h1').text
print(data)
driver.quit()
Headless browsers democratize complex scraping tasks, enabling the extraction of data from pages that require JavaScript execution.
Proxy Management
4.1 Why Use Proxies?
Websites often implement rate limiting and IP blocking mechanisms to prevent excessive requests from a single source. Proxies help distribute requests across multiple IP addresses, reducing the risk of being blocked and ensuring higher scraping reliability.
4.2 Types of Proxies
- Datacenter Proxies: Hosted in data centers, offering high speed and low cost but are easily detectable.
- Residential Proxies: Linked to real residential IP addresses, providing higher anonymity but at a higher cost.
- Rotating Proxies: Change IP addresses with each request or after a set interval, further enhancing anonymity.
4.3 Rotating Proxies and IP Rotation Strategies
IP Rotation Strategies:
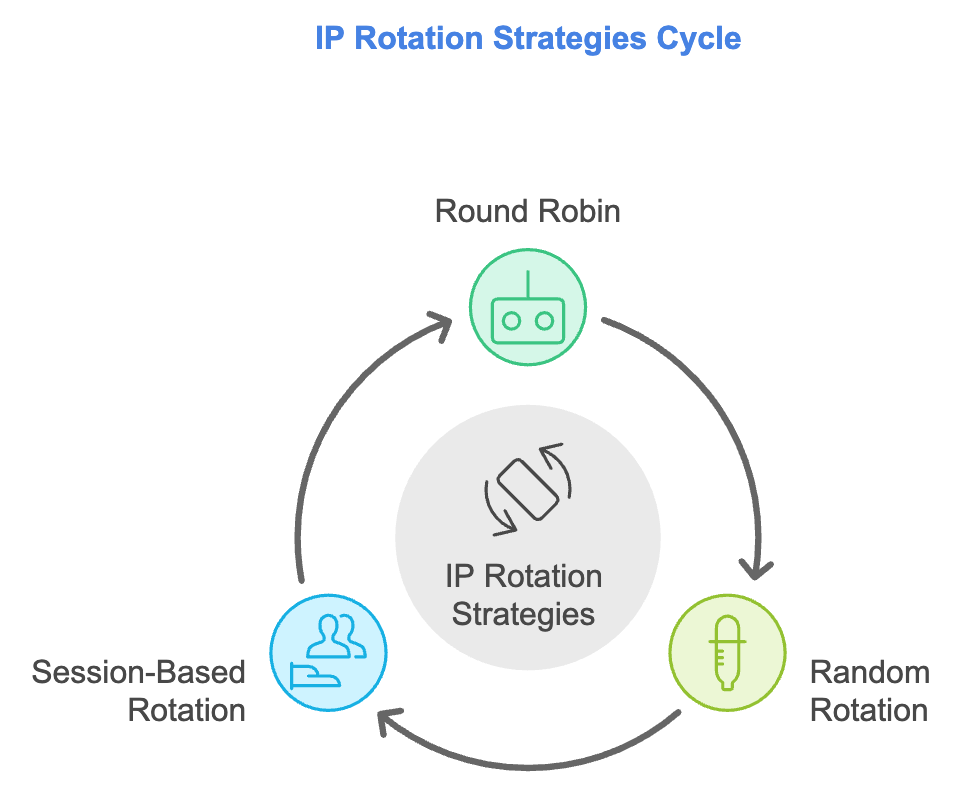
- Round Robin: Sequentially switch between a list of proxy IPs.
- Random Rotation: Randomly select a proxy from the available pool for each request.
- Session-Based Rotation: Assign a specific proxy to a session for a series of requests, maintaining consistency.
Implementing Rotation:
Example: Using Proxy Rotation with Requests in Python
import requests
from itertools import cycle
proxy_list = [
'http://proxy1.com:8000',
'http://proxy2.com:8000',
'http://proxy3.com:8000',
]
proxy_pool = cycle(proxy_list)
url = 'https://example.com'
for i in range(1, 11):
proxy = next(proxy_pool)
try:
response = requests.get(url, proxies={"http": proxy, "https": proxy}, timeout=5)
print(response.status_code)
except:
print("Skipping. Connection error")
4.4 Implementing Proxy Management in Your Scraper
- Proxy Providers: Services like Bright Data (formerly Luminati), Oxylabs, and ScraperAPI offer extensive proxy networks.
- Automated Rotation: Integrate proxy rotation within your scraping framework to switch proxies seamlessly.
- Error Handling: Implement fallback mechanisms to retry requests with different proxies upon encountering failures.
Dealing with Anti-Scraping Measures
5.1 CAPTCHAs
Challenges:
CAPTCHAs are designed to distinguish humans from bots, posing a significant hurdle for scrapers.
Solutions:
- CAPTCHA Solving Services: Services like 2Captcha, Anti-Captcha, and DeathByCaptcha can solve CAPTCHAs programmatically.
- Machine Learning: Implement ML models trained to recognize and solve simple CAPTCHAs.
- Avoid Triggering CAPTCHAs: Mimic human-like behavior to reduce the likelihood of encountering CAPTCHAs.
5.2 Rate Limiting
Challenges:
Websites limit the number of requests from a single IP or over a specific time frame.
Solutions:
- Throttling: Introduce delays between requests to stay within acceptable limits.
- Distributed Requests: Use multiple proxies to spread the request load.
- Respect Robots.txt: Adhere to the website’s
robots.txtguidelines to understand rate limitations.
5.3 Bot Detection Mechanisms
Challenges:
Advanced detection systems analyze patterns like mouse movements, keyboard interactions, and request headers to identify bots.
Solutions:
- Randomizing Headers: Vary User-Agent strings, referers, and other HTTP headers to mimic diverse browsers.
- Headless Browser Stealth: Use tools like puppeteer-extra-plugin-stealth to mask headless browser traits.
- Human-Like Interaction: Simulate human-like interactions, such as scrolling, clicking, and typing, to evade detection.
Optimizing Scraper Performance
6.1 Concurrency and Asynchronous Processing
- Concurrency: Implement multi-threading or multi-processing to handle multiple requests simultaneously.
- Asynchronous Programming: Use asynchronous libraries (e.g., aiohttp in Python) to manage I/O-bound tasks efficiently.
Example: Asynchronous Scraping with aiohttp
import asyncio
import aiohttp
proxy_list = ['http://proxy1.com:8000', 'http://proxy2.com:8000']
async def fetch(session, url, proxy):
async with session.get(url, proxy=proxy) as response:
return await response.text()
async def main():
url = 'https://example.com'
tasks = []
connector = aiohttp.TCPConnector(limit=10)
async with aiohttp.ClientSession(connector=connector) as session:
for proxy in proxy_list:
tasks.append(fetch(session, url, proxy))
responses = await asyncio.gather(*tasks)
for content in responses:
print(content)
asyncio.run(main())
6.2 Efficient Data Storage
- Databases: Use databases like MongoDB, PostgreSQL, or Elasticsearch for structured and scalable data storage.
- Distributed Storage: For massive data volumes, consider distributed storage solutions like Apache Hadoop or Google BigQuery.
- Data Pipelines: Implement pipelines to process and store data in real-time, enhancing efficiency and organization.
Ethical and Legal Considerations
Web scraping operates in a gray area of legal and ethical boundaries. Adhering to best practices ensures responsible scraping:
- Respect Robots.txt: Always check and honor the website’s
robots.txtfile for scraping permissions. - Terms of Service: Review and comply with the website’s terms of service to avoid legal repercussions.
- Data Privacy: Handle personal data responsibly, adhering to regulations like GDPR and CCPA.
- Minimize Server Load: Implement throttling and avoid excessive requests to prevent server strain or denial-of-service impacts.
Top Tools and Libraries for Advanced Web Scraping
- Selenium: A versatile tool for browser automation, supporting multiple programming languages.
- Puppeteer: Ideal for controlling headless Chrome/Chromium, offering powerful scraping capabilities.
- Playwright: Provides cross-browser automation with robust features for handling dynamic content.
- Scrapy: A Python framework tailored for large-scale scraping with built-in support for proxies, middlewares, and pipelines.
- Beautiful Soup: Simplifies HTML parsing and data extraction in Python.
- Requests-HTML: Combines the simplicity of
requestswith HTML parsing and JavaScript execution capabilities.
Best Practices for Advanced Web Scraping
- Plan Your Scraping Strategy: Define clear goals and understand the target website’s structure and technologies.
- Implement Robust Error Handling: Anticipate and manage network issues, timeouts, and unexpected changes in website structure.
- Monitor and Adapt: Continuously monitor scraper performance and adapt to changes in website layouts or anti-scraping measures.
- Maintain Respectful Scraping: Balance data extraction needs with the website’s operational integrity, avoiding actions that could disrupt services.
- Secure Your Infrastructure: Protect your scraping setup against vulnerabilities, ensuring data security and operational reliability.
Conclusion
Advanced web scraping is a powerful skill that combines technical prowess with strategic thinking. By mastering techniques like handling JavaScript-rendered content, leveraging headless browsers, and managing proxies, you can extract valuable data efficiently and responsibly. However, it’s crucial to balance scraping endeavors with ethical considerations and legal compliance to ensure sustainable and respectful data extraction practices. Armed with the knowledge and tools outlined in this guide, you’re well-equipped to navigate the complexities of modern web scraping and harness its full potential for your data-driven projects.
Struggling to Access Data from Challenging Websites? We’ve Got You Covered!
When traditional and advanced web scraping techniques fall short, don’t let valuable data slip away. Our expert team specializes in overcoming the toughest barriers, including JavaScript-rendered content and sophisticated anti-scraping measures. Plus, with our reliable CAPTCHA solving services, we ensure seamless and uninterrupted data extraction tailored to your needs.
Why Choose Us?
- Expertise in Advanced Scraping Techniques: Navigate complex website structures with ease.
- Robust CAPTCHA Solutions: Bypass CAPTCHA challenges effortlessly to keep your projects on track.
- Customized Support: Tailored strategies to meet your unique data requirements.
Don’t let technical hurdles hinder your data-driven decisions. Contact us today and unlock the full potential of web scraping with our comprehensive services!
Additional Resources
- Official Documentation:
Related Articles:
Advanced Web Scraping Techniques: Mastering the Art of Data Extraction