{kind=link}
In today’s world, getting valuable info from the internet is key. Web scraping lets us tap into this data, helping us make smart choices and innovate. As a journalist, I’ve seen how web scraping changes the game for businesses and researchers.
I’ve worked with many clients across different fields. They all want to use online data to their advantage. From keeping an eye on competitors to understanding consumer habits, the need for good data tools is growing.
This guide will take you into the world of web scraping. We’ll cover its basics, benefits, and the tools that can change how you collect data. You’ll learn how to use the internet to find valuable data, from the basics to legal and ethical aspects.
Key Takeaways
- Web scraping is a powerful technique for extracting data from the internet.
- It enables businesses, researchers, and individuals to make data-driven decisions.
- Web scraping can be applied across a wide range of industries, from e-commerce to real estate.
- Understanding the fundamentals and best practices of web scraping is crucial for effective data collection.
- Navigating the legal and ethical considerations is essential for ethical and compliant web scraping.
What is Web Scraping?
Web scraping is the automated way to get valuable data from websites. It helps us collect detailed data from many online places. This data is then ready for analysis and use.
Understanding Web Scraping Fundamentals
Web scraping is about using programs to get data from web pages. It lets us collect data like product info, news, or social media posts. This makes gathering data fast and easy, something we can’t do by hand.
Benefits of Automated Data Extraction
- Increased efficiency in data collection
- Access to comprehensive datasets for informed decision-making
- Ability to stay ahead of the competition by monitoring market trends
- Automated data collection for time-sensitive applications
- Seamless integration of web data into business workflows
Web scraping lets us use online data fully. It changes how we get insights and make decisions.
“Web scraping empowers us to extract valuable data at scale, unlocking a wealth of insights that can drive our business forward.”
Web Scraping Techniques and Tools
Web scraping is all about knowing the different techniques and tools. You can use simple browser extensions or advanced programming frameworks. This section will cover the best web scraping techniques and web scraping tools for extracting data.
Web Scraping Techniques
There are two main ways to scrape the web: manual and automated. Manual scraping means copying data by hand. Automated scraping uses software to do it for you.
- Manual web scraping is good for small tasks. It’s easy but slow for big projects.
- Automated web scraping uses programming languages like Python. It’s faster and better for big projects.
Web Scraping Tools
Many tools help with web scraping, from simple to complex. Here are some popular ones:
- Browser Extensions: Tools like Web Scraper and ParseHub make scraping easy for beginners.
- Dedicated Web Scraping Platforms: Scrapy Cloud and Octoparse offer full platforms for scraping, storing, and analyzing data.
- Programming Frameworks: Developers use frameworks like BeautifulSoup for custom scraping scripts.
| Web Scraping Tool | Key Features | Skill Level |
|---|---|---|
| Web Scraper | Browser-based, visual interface, easy to use | Beginner |
| Scrapy Cloud | Scalable, cloud-based, data storage and analysis | Intermediate |
| BeautifulSoup (Python) | Powerful, flexible, advanced data extraction | Advanced |
Choosing the right web scraping techniques and web scraping tools depends on your project. Think about the data’s complexity, how much you need, and your team’s skills. The right tools and techniques make web scraping easier and more effective.
Setting Up a Web Scraping Project
Starting a web scraping project setup needs a solid plan and clear goals. We’ll show you how to set up your web scraping requirements and create a strong data collection framework.
Defining Objectives and Requirements
The first step is to clearly state your goals and what data you need. Think about these important points:
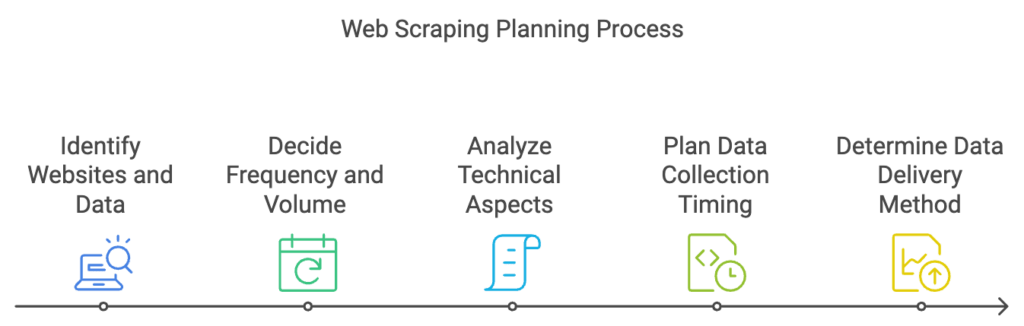
- Find the websites you want to scrape and the data you need. This could be product details, prices, or reviews.
- Decide how often and how much data you need. Is it just once or will you need it often?
- Look at the technical side of the websites you’re targeting. Check their structure, dynamic content, and any anti-scraping tools.
- Plan when you’ll collect the data and if there are any urgent needs.
- Figure out how you want the data delivered. It could be in CSV, JSON, or a database.
By clearly setting up your web scraping project setup and web scraping requirements, you’ll make sure your data collection is efficient and meets your business needs.
“Proper planning and preparation are the keys to a successful web scraping project. Defining clear objectives and requirements upfront will save you time and resources down the line.”
| Objective | Requirement |
|---|---|
| Collect product information from e-commerce sites | Extract product name, description, price, and user reviews |
| Monitor real estate prices in specific neighborhoods | Scrape listing data, including property details, pricing, and images |
| Analyze social media trends and sentiment | Retrieve posts, comments, and engagement metrics from social platforms |
Data Extraction Methods
Web scraping is all about getting useful data from the internet. It starts with parsing HTML and finding the data we need. We’ll look at how web scrapers get data from complex web pages.
Parsing HTML and Retrieving Data
Understanding HTML is key in web scraping. It helps us find and get the data we want. Tools like DOM manipulation, XPath, and regular expressions are crucial.
DOM manipulation lets us work with HTML elements. XPath helps us find specific data in HTML or XML documents. Regular expressions are great for finding text patterns on web pages.
With these skills, web scrapers can get a lot of useful data. This data helps businesses and people make better choices. It gives them insights and keeps them competitive.
Let’s say we want to get product info from an online store. We use DOM manipulation to find the right HTML elements. Then, XPath helps us get the exact data we need. Finally, regular expressions clean up the data for analysis.
Learning to parse HTML is very powerful. It lets web scrapers find valuable data. This data helps them make smart decisions, innovate, and stay ahead in the data world.
Handling Dynamic Websites
The web has changed a lot, with sites using JavaScript and AJAX for content. It’s key to handle these changes well for web scraping dynamic websites and web scraping JavaScript-powered pages. We’ll look at ways to get data from these complex, always-changing sites.
Rendering JavaScript-Heavy Pages
Today, many sites use JavaScript to change and update their content. Old web scraping tools can’t get this data. We can use headless browsing to render JavaScript and get the info we need.
- Use tools like Puppeteer or Selenium for headless browsing.
- Keep up with website changes that might affect JavaScript, so update your scripts often.
- Use browser tools and network monitoring to track data flow and find important AJAX requests.
Intercepting AJAX Requests
Modern sites often use AJAX to update content without refreshing the page. This makes it hard for traditional scraping. We can catch AJAX requests and get the data from the response.
- Look at network traffic to find the AJAX requests and the data they send back.
- Use tools like Puppeteer or Selenium to make the AJAX requests and get the data.
- Use caching and request limits to reduce the load on the site and your scraping setup.
Learning these methods for web scraping dynamic websites and web scraping JavaScript content lets you get data from complex, changing sites.
Web Scraping Techniques for Different Data Types
The world of web data is vast and diverse. It includes structured tabular data, unstructured text, and multimedia content. As web scraping enthusiasts, we must be ready to handle this variety. We need to extract and use the information that’s most valuable to our projects.
When web scraping different data types, we face unique challenges and techniques. Let’s look at some key data types and the web scraping methods for each:
Structured Data
Structured data, like tables and databases, is easy to extract. We use HTML parsing libraries to find and extract the data we need. This is often done with high accuracy and efficiency.
Unstructured Text
Unstructured text, such as articles and social media posts, is harder to scrape. But, by using natural language processing (NLP) techniques, we can find important information. This includes keywords, sentiment, and named entities.
Multimedia Content
Getting multimedia content, like images and videos, from websites needs special techniques. We use web scraping tools to find and download these assets. This lets us use them in our data-driven projects.
| Data Type | Scraping Technique | Potential Challenges |
|---|---|---|
| Structured Data | HTML parsing | Inconsistent table structures, dynamic content |
| Unstructured Text | NLP, text extraction | Identifying relevant information, handling complex formatting |
| Multimedia Content | Asset identification and download | Handling different media formats, dealing with CDN URLs |
By learning these web scraping techniques for various data types, we can find a lot of valuable information online. This puts us in a good position for success in many data-driven projects.
Data Cleaning and Preprocessing
Web scraping is a powerful tool for getting valuable data from the internet. But, the raw data often needs a lot of cleaning and preprocessing before it’s useful. We’ll look at why data cleansing is important and how to fix common problems like inconsistencies and missing values.
Handling Inconsistencies and Errors
Scraped data often has mistakes like misspellings and formatting issues. Web scraping data cleaning and web scraping data preprocessing are key to making your data reliable. By fixing these problems, you can turn your raw data into something clean and useful.
Missing values or incomplete data are common in web scraping. This can happen for many reasons, like website changes or broken links. Using techniques like imputation can help fill in these gaps, making your dataset more complete.
Formatting issues can also be a problem when scraping data from different sources. Problems like different date formats or currency symbols can make analysis hard. Making sure all data is in the same format is a big part of web scraping data preprocessing.
| Web Scraping Data Cleaning Techniques | Web Scraping Data Preprocessing Approaches |
|---|---|
| Identifying and addressing missing valuesCorrecting spelling and typographical errorsStandardizing data formats and unitsHandling outliers and anomalies | Data imputation and interpolationNatural language processing for text normalizationAutomated data transformation and conversionAnomaly detection and filtering |
By using web scraping data cleaning and preprocessing, you can make your raw data into something high-quality and reliable. This data is then ready for further analysis and use.
Storing and Managing Scraped Data
Web scraping is now key for businesses and researchers. Managing the huge amounts of data collected is vital. Using strong data storage solutions is essential to keep your data valuable and easy to access.
Database Integration
Storing web-scraped data in a database is very effective. It offers many benefits, including:
- Structured data storage for easy retrieval and analysis
- Scalability to handle growing volumes of web scraping data
- Improved data integrity and security through database management features
- Seamless integration with other data-driven applications and workflows
Choosing the right database for web scraping data storage and web scraping database integration is crucial. Relational databases, NoSQL databases, and cloud-based solutions are popular. Each has its own strengths and things to consider.
| Database Type | Advantages | Considerations |
|---|---|---|
| Relational Databases | Structured data storageRobust querying capabilitiesMature ecosystem and tooling | Scalability limitations for big dataComplexity in managing schema changes |
| NoSQL Databases | Flexible schema for unstructured dataScalability and high availabilityOptimized for high-volume, high-velocity data | Limited querying capabilities compared to SQLPotential for increased complexity in data modeling |
| Cloud-based Solutions | Scalability and on-demand provisioningReduced infrastructure management overheadIntegrated data processing and analytics tools | Potential for increased costs at scaleReliance on cloud provider’s infrastructure and services |
Choosing the right database is important. You need a system that fits your web scraping goals and your organization’s needs. By focusing on web scraping data storage and web scraping database integration, you can make the most of your data. This turns raw data into useful insights.
Web Scraping for Specific Industries
Web scraping is a key tool for businesses in many fields. We’ll look at e-commerce and real estate, where web scraping really helps. Knowing what data these areas need and how to get it can boost your business.
E-commerce and Price Monitoring
For e-commerce, web scraping is a big deal for watching prices. It lets online stores keep up with competitors and set prices wisely. This way, they can stay competitive and make more money. Web scraping for e-commerce helps track price changes and keep up with market trends.
Real Estate and Property Data
In real estate, web scraping for real estate is crucial for getting property data. It helps professionals make smart choices and spot trends. Web scraping makes finding and analyzing data easier, helping real estate companies advise better.
Web scraping is a game-changer for businesses in many areas. It helps them get valuable insights and make better decisions. By using web scraping, companies can gain a big advantage in their markets.
Advanced Web Scraping Techniques
As your web scraping needs grow, it’s key to learn advanced techniques. We’ll look into distributed web scraping and how to scale up your data extraction. We’ll also cover performance optimization techniques to make your web scraping faster and more reliable.
Distributed Web Scraping
Distributed web scraping uses many machines to extract data. This method makes your web scraping faster and more efficient. It’s great for big projects or websites that get a lot of traffic.
- Leverage cloud-based infrastructure for scalable and reliable data extraction
- Implement load-balancing techniques to distribute requests across multiple servers
- Utilize parallel processing to extract data from multiple sources simultaneously
- Ensure seamless coordination and communication between distributed components
Scalability and Performance Optimization
As your web scraping grows, you need to make it faster and more efficient. This means handling more traffic, using resources wisely, and keeping your data reliable.
- Implement caching mechanisms to reduce redundant requests and improve response times
- Optimize network connections and reduce latency by leveraging content delivery networks (CDNs)
- Utilize asynchronous processing to handle concurrent requests and improve overall throughput
- Monitor and manage system resources, such as CPU, memory, and bandwidth, to prevent bottlenecks
By learning these advanced web scraping techniques, you can handle big data challenges. You’ll make your web scraping scalable and get valuable insights from the internet.
| Technique | Description | Benefits |
|---|---|---|
| Distributed Web Scraping | Leveraging multiple servers or cloud-based infrastructure to scale up data extraction | Increased speed, throughput, and reliability of web scraping operations |
| Performance Optimization | Implementing strategies to handle increased traffic, optimize resource usage, and ensure reliability | Improved response times, reduced latency, and enhanced overall system performance |
Web Scraping Challenges and Solutions

Web scraping is a powerful tool for getting data from the internet. But, it comes with its own set of challenges. As websites change, web scrapers need to stay quick and find solutions. They face issues like website layout changes, CAPTCHA puzzles, and IP address limits.
Keeping up with website changes is a big challenge. Websites often update their designs and content. To deal with this, web scrapers must watch websites closely and update their scripts. Using a modular approach helps keep scraping effective.
CAPTCHA puzzles are another hurdle. They aim to tell humans from bots. Web scrapers can use OCR, machine learning, or third-party services to solve them. Being persistent and trying different methods is crucial.
IP address limits are also a problem. Websites may limit requests from one IP address. To get around this, web scrapers can use proxy servers, rotate IPs, or use residential proxies.
By understanding web scraping challenges and finding web scraping solutions, web scrapers can keep their data gathering effective. They need to keep learning, be adaptable, and strategic in the changing web scraping world.
Monitoring and Maintenance
Web scraping is a continuous task that needs constant attention and flexibility. We’ll look at ways to keep up with website changes. This ensures your scraping scripts work well all the time. By watching target websites closely, handling errors, and updating workflows, you keep your web scraping monitoring and web scraping maintenance strong.
Detecting and Handling Website Changes
Websites change often, affecting their structure, content, and tech. It’s key to watch for these web scraping website changes to stay on track. Use systems to quickly spot and notify you of any changes. Look for updates in HTML, URL changes, or tech stack changes.
- Set up automated checks to watch for website changes and alert you to any.
- Make sure your scraping scripts can handle and recover from changes smoothly, keeping your data collection going.
- Use flexible scraping scripts that can easily adjust to website updates, saving you time.
By being alert and quickly fixing web scraping website changes, your web scraping monitoring and web scraping maintenance will stay strong and reliable.
| Metric | Importance for Web Scraping Monitoring | Recommended Monitoring Frequency |
|---|---|---|
| HTML Structure Changes | Ensures your scraping scripts can continue to locate and extract the desired data | Daily |
| URL Changes | Helps you identify and adapt to changes in the website’s navigation and page structure | Weekly |
| Technology Stack Updates | Allows you to adjust your scraping approaches to remain compatible with the site’s underlying infrastructure | Monthly |
“Continuous monitoring and proactive adaptation are the keys to sustainable web scraping success.”
Web Scraping Workflows and Automation
Efficiency and scalability are crucial in web scraping. To get the most out of your data, setting up clear web scraping workflows is key. Using web scraping automation helps make the process smoother and more efficient.
Creating web scraping workflows lets us tie data collection to our analysis pipelines. This way, web scraping isn’t just a separate task. It’s part of a bigger process that includes cleaning, transforming, and analyzing data.

- Automating tasks like scheduling and monitoring saves time and ensures data is collected regularly.
- Using Application Programming Interfaces (APIs) offers a structured way to get data, making scraping easier.
- Connecting web scraping workflows with data storage solutions helps manage data better and supports advanced analytics.
Automating web scraping boosts our ability to handle more data. This lets us adapt to business needs more easily.
“Web scraping workflows and automation are key to unlocking the full potential of data extraction from the internet.”
The aim is to build a web scraping system that works well with your data analysis and decision-making. By focusing on web scraping workflows and automation, we can turn raw data into insights that help businesses grow.
Legal and Ethical Considerations
Exploring web scraping means we must be careful with legal and ethical rules. Web scraping is powerful, but we must follow website rules. Not following these rules can cause legal problems and harm our reputation.
Website Terms of Service
Before starting a web scraping project, check the website’s terms of service. These rules tell us what we can and can’t do with the data. Breaking these rules can lead to serious legal trouble, like fines or lawsuits.
Data Privacy and Security
Data privacy and security are key when web scraping. The data we get might include personal info, which we must protect. We must make sure this data is safe and follow laws like the General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA).
By focusing on web scraping legal considerations, web scraping ethics, web scraping data privacy, and web scraping security, we make sure our projects are good and legal. This way, we avoid legal issues and keep the data we collect trustworthy and safe.
Conclusion
In this guide, we’ve looked at how web scraping changes the game. We covered its basics, methods, and uses. You now know how to use web scraping to find valuable data and stay legal and ethical.
As we wrap up, remember to always keep your data safe and secure. Also, keep up with changes in the web world. Web scraping can help you make smart choices, get ahead of the competition, and find new chances online.
The world of web scraping is always changing. We urge you to keep learning, try new things, and work with experts. The secret to web scraping success is finding the right balance between new ideas, following the rules, and being ethical. This balance will help your business grow in the digital world.
FAQ
What is web scraping?
Web scraping is when you automatically pull data from websites. It uses programs to get specific info from web pages. This can be things like product details or social media posts.
What are the benefits of web scraping?
Web scraping helps you get lots of information quickly. It lets you make data-driven decisions fast. You can also understand market trends and stay ahead of competitors.
What are some common web scraping techniques and tools?
Common techniques include parsing HTML and using XPath. Popular tools are browser extensions and frameworks like Python’s BeautifulSoup and Scrapy.
What are the legal and ethical considerations for web scraping?
Always check website terms of service. Make sure you’re not breaking any rules. Also, keep the data you collect safe and private.
How do I set up a successful web scraping project?
First, know what you want to achieve. Then, pick the websites you want to scrape. Lastly, plan how you’ll get the data you need.
How do I handle dynamic websites with JavaScript and AJAX?
For dynamic sites, you need special techniques. Use headless browsers or simulate user actions to get the data you need.
How do I handle different data types when web scraping?
You need different approaches for different data types. Whether it’s structured data or text, know what you’re dealing with.
How do I clean and preprocess the data extracted through web scraping?
The data you get might need a lot of cleaning. Fixing errors and making it consistent is key. Automating this process helps a lot.
How do I store and manage the data collected through web scraping?
You’ll need to store the data in a way that makes sense. Use databases and other solutions to keep it organized and accessible.
How can web scraping be applied in specific industries?
Web scraping is useful in many fields. For example, in e-commerce for price checks or in real estate for property data. It helps solve big business problems.
What are some advanced web scraping techniques?
As you get more into web scraping, you might want to try more advanced methods. This includes using multiple servers or cloud services for better performance.
What are some common web scraping challenges and solutions?
You might face issues like changing website structures or CAPTCHA challenges. Use error-handling and automate updates to solve these problems.
How do I monitor and maintain my web scraping efforts?
Keep an eye on your web scraping and make adjustments as needed. Use error-handling and automate updates to keep things running smoothly.
How can I integrate web scraping into my overall data collection and analysis workflows?
Make web scraping a part of your data workflow. Use automation to make it more efficient. This will help you get the most out of web scraping for your business.